Section 1: The Problem
Modern lawsuits do not run on a few boxes of paper anymore. They run on emails, chats, spreadsheets, PDFs, phone exports, shared-drive folders, and years of internal records. Before trial, each side often has to search that material, find responsive documents, protect privileged ones, and produce the rest.
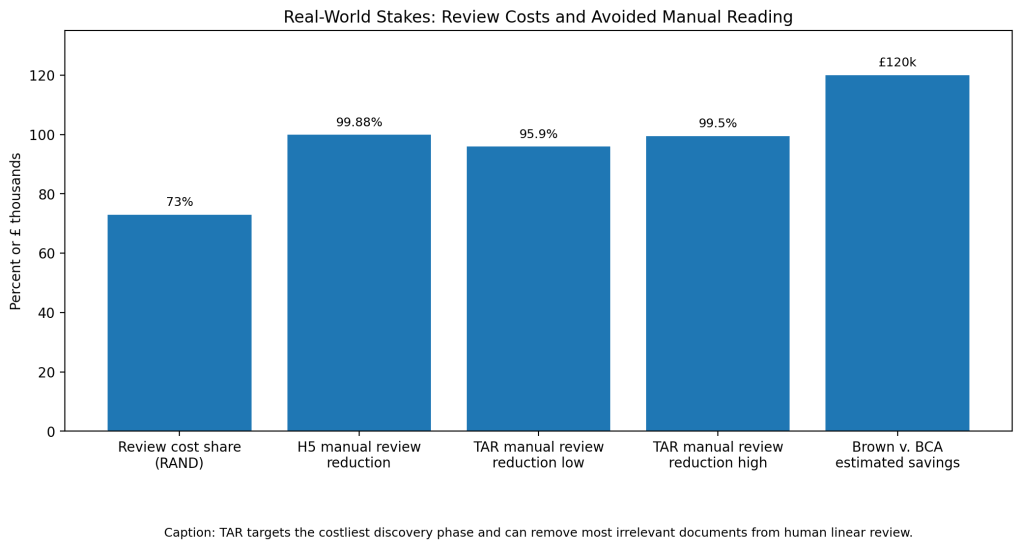
That review step is the expensive part. RAND found that e-discovery costs break into collection, processing, and review, with review taking 73% of production costs. RAND also warned that when cases involve tens of thousands or millions of emails and electronic documents, eyes-on legal review creates enormous labor costs.
Traditional review uses lawyers or contract reviewers to read documents one by one. That sounds careful, but it is slow, expensive, and inconsistent. Human reviewers get tired. Different reviewers disagree. Important documents can hide inside ordinary-looking email chains.
Section 2: What Research Shows
Technology-assisted review, or TAR, changes the task. A senior reviewer labels sample documents, then a model learns patterns tied to relevance. The system ranks the remaining pile so humans start with likely important material instead of reading everything in order.
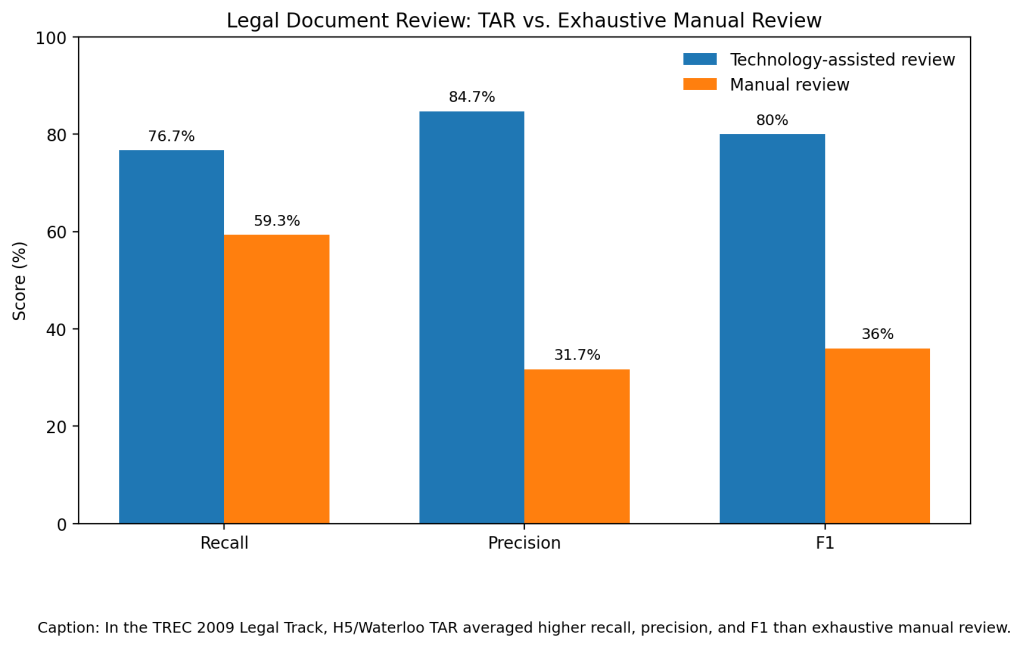
The classic evidence comes from Grossman and Cormack’s TREC 2009 Legal Track analysis. Across five topics, H5 and Waterloo’s technology-assisted reviews averaged 76.7% recall, 84.7% precision, and 80.0% F1. Exhaustive manual review averaged 59.3% recall, 31.7% precision, and 36.0% F1. The authors found TAR beat manual review on average, especially on precision and F1.
Recent TAR research still points to the same idea: humans and models work best together. Di Nunzio’s 2024 survey says TAR systems are used in high-precision document screening, including e-discovery, and that newer machine learning and LLM methods expand what these systems can handle. The same survey flags key technical problems, including stopping rules, high-quality domain datasets, reproducibility, and defensibility.
Section 3: What the Real World Shows
The practical gain is workload reduction. In one H5 legal review effort, the team examined only 7,992 documents instead of the 6,910,192 documents that exhaustive manual review would have required. Grossman and Cormack describe that as roughly 860 times fewer documents reviewed.
The 2009 TAR efforts also reviewed only 0.5% to 4.1% of the collection across topics. That means the model did not replace lawyers. It changed where lawyers spent their attention. Instead of spreading hours across the entire pile, reviewers focused on the documents most likely to matter.
Courts have accepted this logic in real cases. Da Silva Moore v. Publicis Groupe became the first major U.S. case to approve computer-assisted review for e-discovery, and later cases continued to debate when TAR should be used, who controls the protocol, and who pays. Everlaw’s legal guide cites Brown v. BCA Trading as an example where predictive coding was estimated to save about £120,000 compared with traditional linear review.
Section 4: The Implementation Gap
The first gap is trust. Lawyers have to defend their review process to courts, clients, and opposing counsel. A model that says “not relevant” is hard to trust when the missed document could decide a case. Thomson Reuters says predictive coding has not become everyday practice partly because it requires specialized skills, costs money to implement, and still makes risk-averse lawyers worry about court reception.
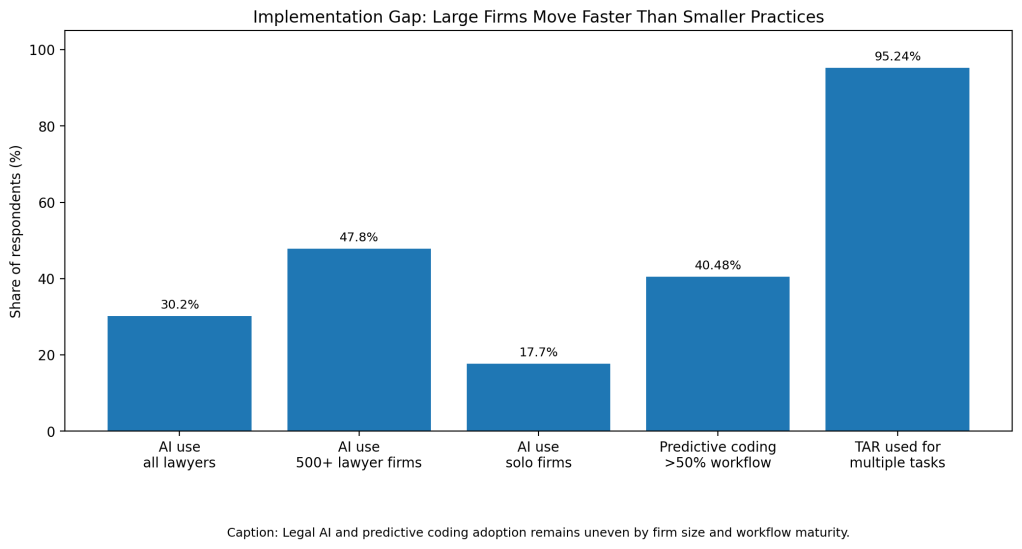
The second gap is uneven adoption. ABA’s 2024 Artificial Intelligence TechReport found that 30.2% of surveyed lawyers said their offices used AI-based tools. Usage was 47.8% in firms with 500 or more lawyers, but only 17.7% among solo practitioners. Big firms can absorb software cost, training, data hosting, and technical support. Small practices often cannot.
The third gap is workflow maturity. In a 2021 ComplexDiscovery survey, 40.48% of respondents said they used predictive coding in more than half of their e-discovery workflow, while 95.24% used TAR for more than one discovery task. That means experienced users often expand usage, but the industry still has a split between mature teams and teams that barely use it.
The fourth gap is defensibility. Remus argues that predictive coding has real potential but is not a magic fix for discovery abuse, cost, or trust. Her concern is that vendors and courts sometimes treat predictive coding as a clean solution when the process still depends on human training choices, transparency, and professional judgment.
Section 5: Where It Actually Works
TAR works best when the case has a large document set, clear review goals, senior lawyer training, statistical validation, and a documented protocol. Everlaw describes predictive coding as a supervised learning process where lawyers train the model, validate output, and keep humans involved before production. It also warns that TAR struggles with scanned PDFs, images, foreign-language documents, embedded data, and poorly managed training sets.
It also works when both sides know the rules early. A clear protocol answers practical questions before the fight starts: What counts as relevant? Who trains the model? What recall target is acceptable? How will sampling validate the result? Without that structure, TAR becomes another discovery dispute instead of a way to reduce one.
Section 6: The Opportunity
The opportunity is not “AI replaces lawyers.” The opportunity is using data science to make legal review less wasteful and more consistent. TAR helps lawyers find the likely evidence sooner, reduce irrelevant reading, and show courts a measurable review process.
The future version should be more transparent than early predictive coding. Legal teams need systems that show recall, precision, confidence thresholds, review history, seed-set quality, and validation samples. If courts and lawyers can inspect the process, they are more likely to trust the result.
References
[1] RAND Corporation. “Predictive Coding Could Reduce E-Discovery Costs, but More Guidance Needed on Data Preservation.” 2012.
[2] Grossman, Maura R., and Gordon V. Cormack. “Technology-Assisted Review in E-Discovery Can Be More Effective and More Efficient Than Exhaustive Manual Review.” Richmond Journal of Law and Technology, 2011.
[3] Di Nunzio, Giorgio Maria. “Technology Assisted Review Systems: Current and Future Directions.” ALTARS, 2024.
[4] Ireland, Gordon T., and Gordon V. Cormack. “Comparison of Tools and Methods for Technology-Assisted Review.” 2024.
[5] Remus, Dana A. “The Uncertain Promise of Predictive Coding.” Iowa Law Review, 2014.
[6] American Bar Association. “2024 Artificial Intelligence TechReport.” 2025.
[7] ComplexDiscovery. “Predictive Coding Technologies and Protocols Survey, Fall 2021 Results.” 2021.
[8] Thomson Reuters. “How Predictive Coding Makes E-Discovery More Efficient.” 2023.
[9] Everlaw. “Predictive Coding.” Everlaw Guide to Ediscovery, 2025.
[10] EDRM. “Technology Assisted Review.” Electronic Discovery Reference Model.

Leave a comment