Section 1: The Problem
Bad software is not a small technical nuisance. In 2022, poor software quality cost the United States at least $2.41 trillion, while accumulated technical debt reached about $1.52 trillion (Krasner). CISQ also tied the problem to vulnerability-driven cybercrime, software supply-chain risk, and a shortage of roughly 300,000 IT workers (Krasner).
Traditional quality assurance still depends heavily on code review, developer judgment, and broad testing. Those methods matter, but they waste time when every file receives similar attention. A better system would flag the changes most likely to break production before they reach users.
Section 2: What Research Shows
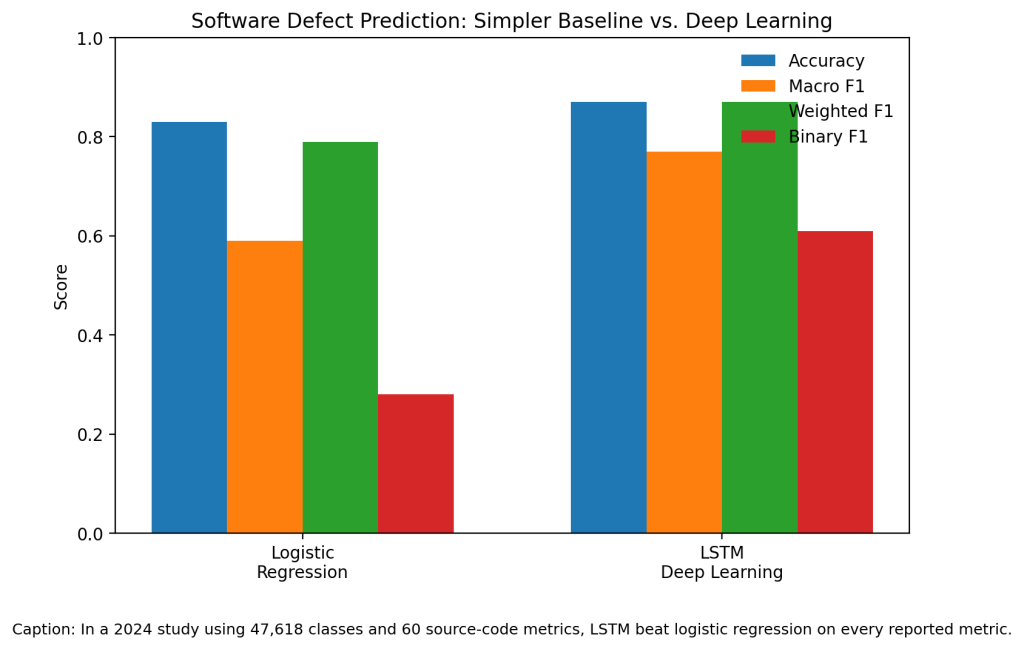
Machine learning defect prediction tries to do exactly that. Instead of treating each code change equally, models learn from past commits, code complexity, churn, coupling, size, and bug history. In one 2024 study using 47,618 classes and 60 source-code metrics, an LSTM deep learning model reached 0.87 accuracy, 0.77 macro F1, 0.87 weighted F1, and 0.61 binary F1. Logistic regression reached 0.83 accuracy, 0.59 macro F1, 0.79 weighted F1, and 0.28 binary F1 (Albattah and Alzahrani).
The broader research base is also large. Giray and colleagues reviewed 102 peer-reviewed deep learning studies on software defect prediction and found supervised deep learning dominated the field, with convolutional neural networks used most often (Giray et al.).
Section 3: What the Real World Shows
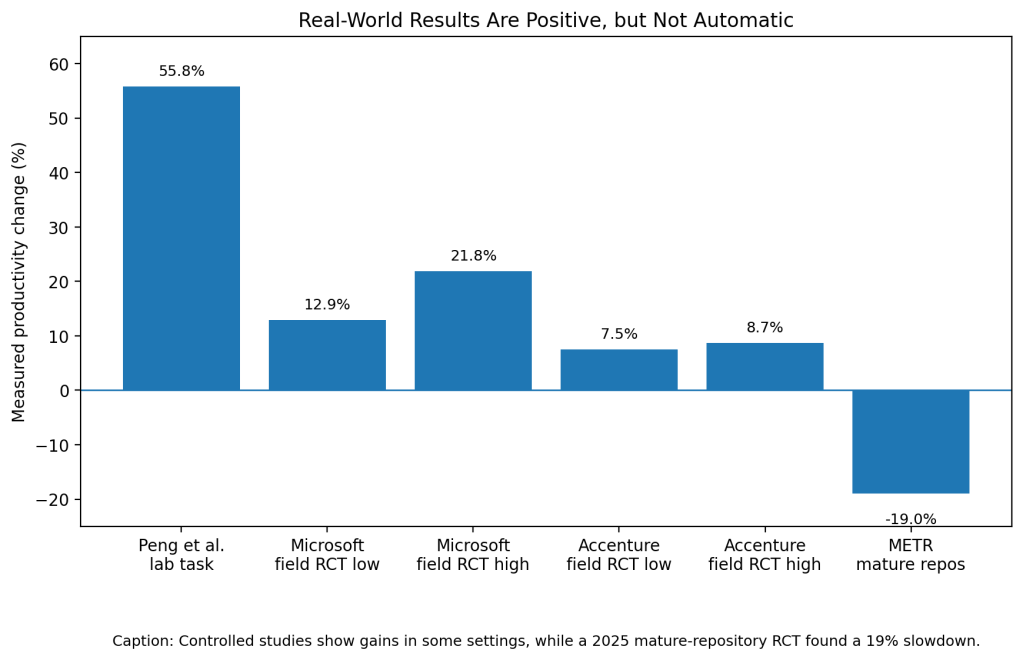
AI coding tools show real gains in controlled settings, but the results depend on context. Peng and colleagues ran a controlled GitHub Copilot experiment where developers built a JavaScript HTTP server. The Copilot group finished 55.8% faster than the control group (Peng et al.).
A larger field experiment studied about 2,000 developers at Microsoft and Accenture. Developers with Copilot completed 12.92% to 21.83% more pull requests per week at Microsoft and 7.51% to 8.69% more at Accenture, depending on the model specification (Cui et al.). The study also warned the estimates were not perfectly precise because of low Microsoft uptake and organizational changes at Accenture (Cui et al.).
The evidence is not all positive. A 2025 randomized trial by Becker and colleagues studied 16 experienced open-source developers completing 246 real tasks in mature repositories. Developers expected AI to make them 24% faster, but AI access made them 19% slower (Becker et al.).
Section 4: The Implementation Gap
The problem is not lack of models. It is lack of usable models. Stradowski and Madeyski found only 32 in-vivo studies out of 397 papers found through automatic search. Their review says industry application still lags behind academic progress and that papers often give little evidence on cost, deployment lessons, or business value (Stradowski and Madeyski).
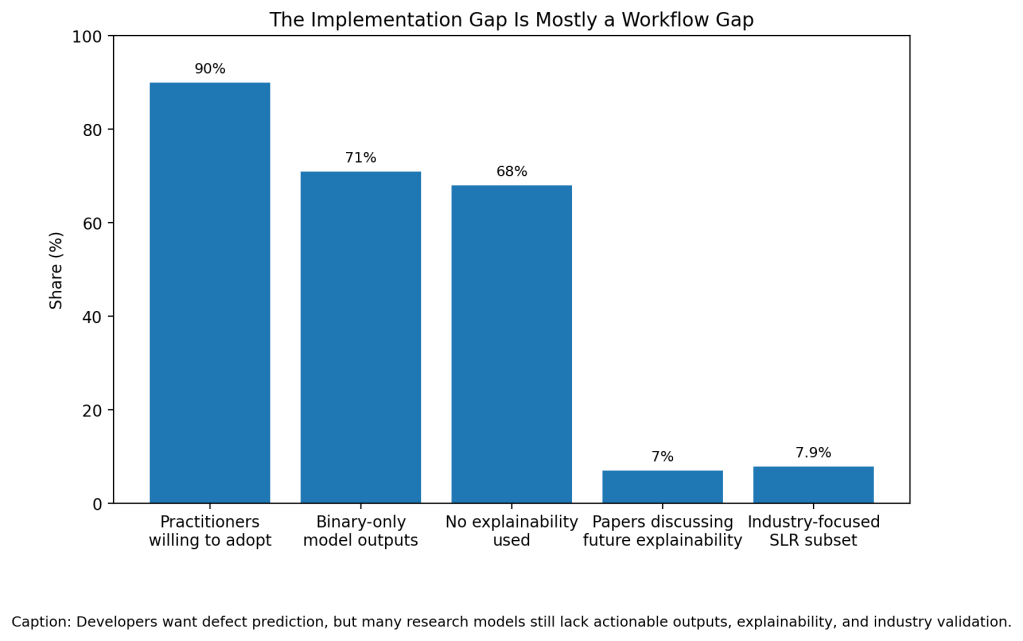
Developers also need explanations, not only warnings. Grattan and colleagues reviewed 132 papers and found 71% of models produced binary outputs, 68% used no explainability, and only 7% even listed explainability as future work (Grattan et al.). A warning that says “bug-prone” gives a reviewer more work. A warning that says “high-risk because this commit changes shared state, touches a fragile file, and resembles three past failures” gives a reviewer direction.
Trust is another barrier. Wan and colleagues surveyed 395 practitioners across 33 countries. More than 90% said they were willing to adopt defect prediction, but the study found a disconnect between practitioner beliefs and research evidence (Wan et al.).
Section 5: Where It Actually Works
These tools work best when they sit inside the developer workflow. The Microsoft and Accenture field trial worked because Copilot fit into normal coding, pull requests, and review systems (Cui et al.).
Defect prediction also works better when teams validate models on their own data. Stradowski and Madeyski recommend mixed validation using research, open-source, and industrial datasets before deployment (Stradowski and Madeyski).
Section 6: The Opportunity
Software defect prediction should shift from “AI finds bugs” to “AI helps teams spend review time where risk is highest.” The evidence supports the idea, but adoption needs better workflow design.
References
[1] Krasner, Herb. The Cost of Poor Software Quality in the US: A 2022 Report. Consortium for Information & Software Quality, 2022.
[2] Albattah, Waleed, and Musaad Alzahrani. “Software Defect Prediction Based on Machine Learning and Deep Learning Techniques: An Empirical Approach.” AI, vol. 5, no. 4, 2024, pp. 1743-1758.
[3] Giray, Görkem, et al. “On the Use of Deep Learning in Software Defect Prediction.” Journal of Systems and Software, 2023.
[4] Stradowski, Szymon, and Lech Madeyski. “Industrial Applications of Software Defect Prediction Using Machine Learning: A Business-Driven Systematic Literature Review.” Information and Software Technology, vol. 159, 2023.
[5] Grattan, Natalie, Daniel Alencar da Costa, and Nigel Stanger. “The Need for More Informative Defect Prediction: A Systematic Literature Review.” Information and Software Technology, vol. 171, 2024.
[6] Wan, Zhiyuan, et al. “Perceptions, Expectations, and Challenges in Defect Prediction.” IEEE Transactions on Software Engineering, vol. 46, no. 11, 2020, pp. 1241-1266.
[7] Peng, Sida, et al. “The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.” arXiv, 2023.
[8] Cui, Kevin Zheng, et al. “The Productivity Effects of Generative AI: Evidence from a Field Experiment with GitHub Copilot.” MIT GenAI, 2024.
[9] Becker, Joel, et al. “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” arXiv, 2025.
[10] Zeng, Zhengran, et al. “Deep Just-in-Time Defect Prediction: How Far Are We?” ISSTA, 2021.

Leave a comment