Section 1: The Problem
Researchers do not suffer from too little evidence. They suffer from too much of it. A systematic review often takes about 67 weeks to complete, and screening search results is one of the most labor-heavy steps (Scott et al.).
The work is simple but exhausting. Reviewers search databases, remove duplicates, then read thousands of titles and abstracts to decide which papers deserve full review. Research Screener’s 2021 paper notes that title and abstract screening often requires analysts to review thousands of articles manually and takes about 33 days on average (Chai et al.).
Traditional screening protects quality by using humans, often two independent reviewers. The problem is scale. When a search returns 8,000 or 15,000 records, most are irrelevant. Reviewers spend huge time rejecting papers that a model often learns to rank near the bottom.
Section 2: What Research Shows
Machine learning screening tools work by learning from early human decisions. As reviewers include or exclude records, the model starts ranking unseen papers by likely relevance. Ferdinands and colleagues tested active learning models across six systematic review datasets and found that models reduced the number of papers needing screening by 63.9% to 91.7% while still finding 95% of relevant records (Ferdinands et al.).
Cochrane’s RCT Classifier gives another strong example. Thomas and colleagues trained it on 280,620 title-abstract records, including 20,454 records reporting randomized controlled trials. The final classifier retrieved 43,783 of 44,007 eligible RCTs, which equals 99.5% recall, while missing 224 records, or 0.5% (Thomas et al.).
LLMs are now entering the same workflow. Matsui and colleagues tested a 3-layer GPT-3.5 and GPT-4 screening method on two prior systematic reviews with 1,381 and 3,146 records. GPT-4 reached adjusted sensitivity and specificity of 0.962 and 0.996 in the first review, and 0.943 and 0.855 in the second review (Matsui et al.).
Section 3: What the Real World Shows
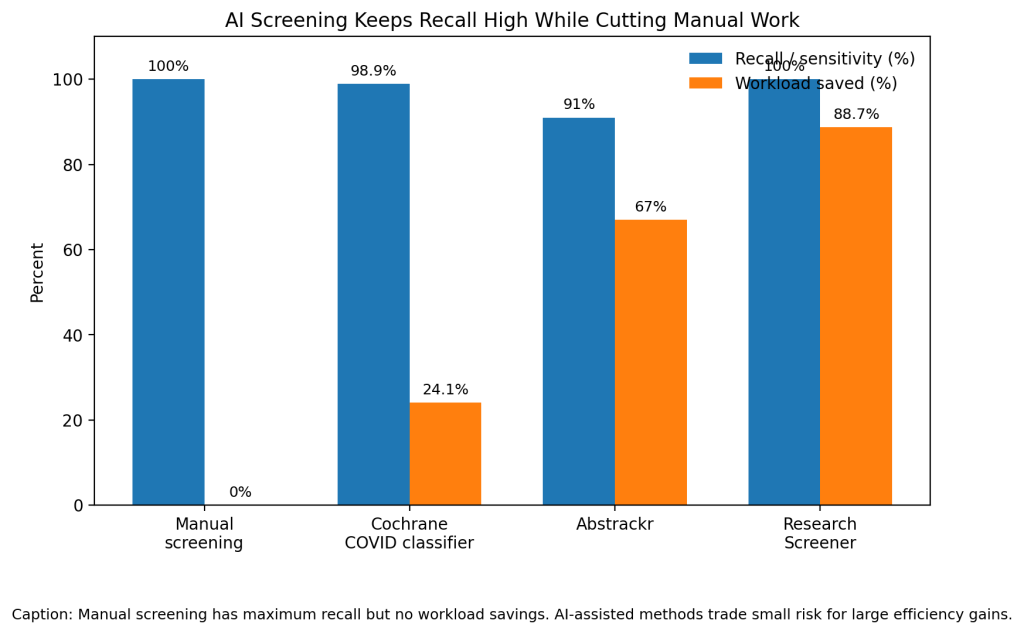
The strongest real-world example comes from Cochrane. Shemilt and colleagues built the Cochrane COVID-19 Study Classifier for a live COVID-19 research register. It trained on 59,513 records, calibrated on 16,123 records, then retrieved 2,285 of 2,310 eligible records in final testing. That equals 98.9% recall, 0.638 precision, and a 24.1% net screening workload reduction (Shemilt et al.).
Abstrackr also showed practical time savings. Carey and colleagues tested it on 7,723 records from a systematic review. Abstrackr reduced Stage 1 workload by 67%, saved 5.4 days, reached 91% sensitivity, and did not omit any citation that later made it through full-text screening (Carey et al.).
Research Screener reported even larger savings. Chai and colleagues found workload savings from 60% to 96% across nine systematic reviews and two scoping reviews. In a real-world interactive analysis, the tool saved 12.53 days and about $2,444 compared with manual screening (Chai et al.).
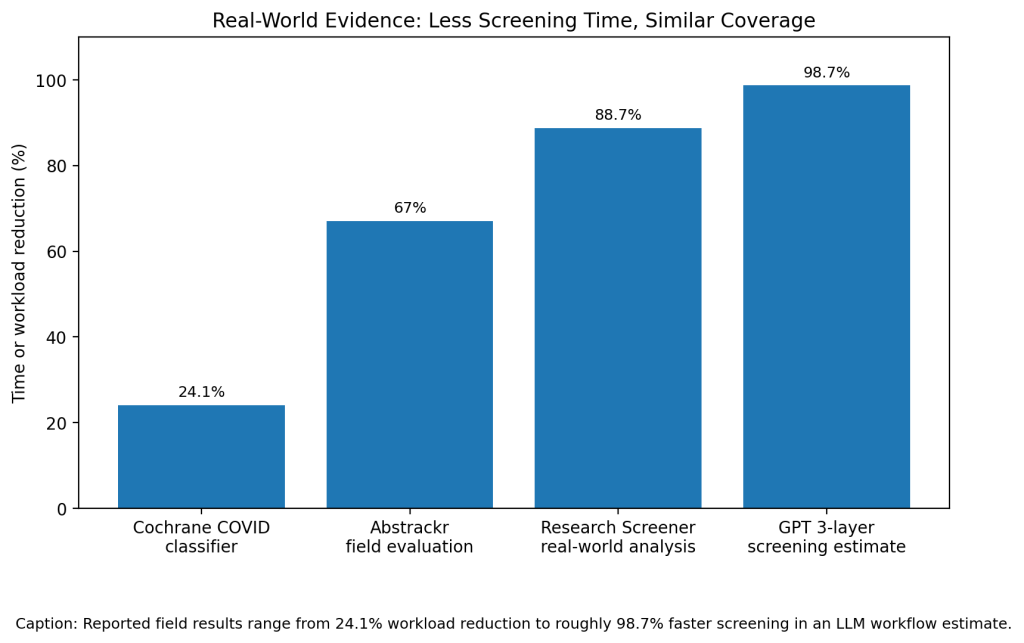
Section 4: The Implementation Gap
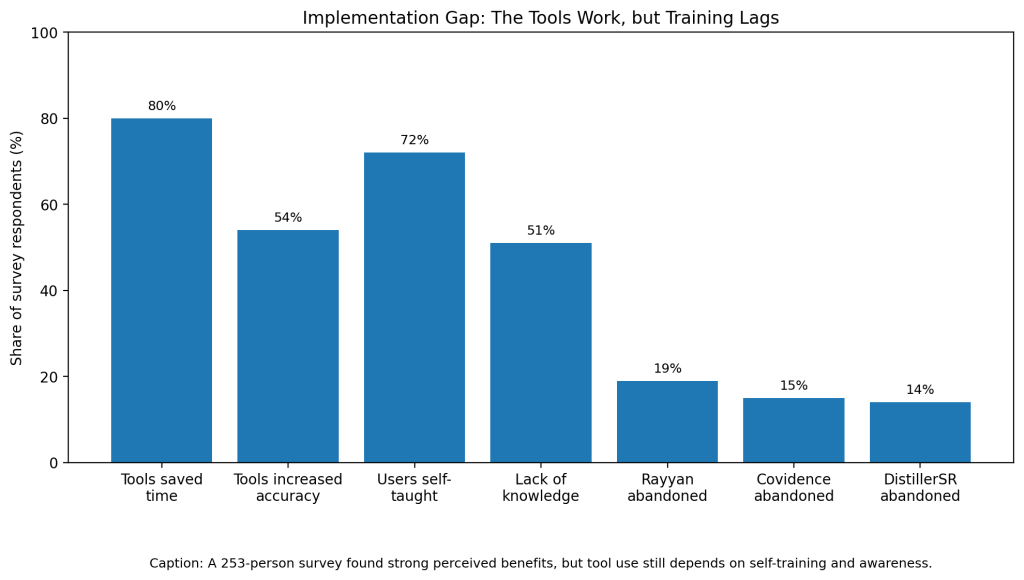
The evidence looks strong, but adoption still lags. Scott and colleagues surveyed 253 evidence synthesis users and found that 89% had used automation tools, but use clustered around a few platforms. Tools saved time for 80% of respondents and increased accuracy for 54%, yet 51% named lack of knowledge as the main adoption barrier (Scott et al.).
Training is a major issue. In the same survey, 72% of respondents said they taught themselves how to use the tools. That matters because screening automation is not plug-and-play. A bad stopping rule, poor inclusion criteria, or weak seed set can turn a useful model into a risk (Scott et al.).
Trust is the second barrier. O’Connor and colleagues argue that reviewers hesitate because they do not fully trust automation, struggle with setup, and worry about matching tools to existing production workflows (O’Connor et al.).
False positives also create friction. Carey’s Abstrackr study found 2,001 false positives, which lowered specificity to 72% and precision to 15.5%. The tool saved time at title-abstract screening, but it also risked pushing extra papers into full-text review (Carey et al.).
Section 5: Where It Actually Works
AI screening works best when teams use it as a prioritization layer, not a replacement for judgment. Cochrane’s COVID classifier succeeded because it entered a live workflow with a high-recall threshold and human oversight. The tool reduced manual screening while keeping the risk of missed studies low (Shemilt et al.).
Research Screener also worked because it kept humans in the loop. Reviewers still made decisions, but the model moved likely relevant records to the front. Chai and colleagues found researchers could screen 50% of the article pool and still be highly likely to identify all eligible papers (Chai et al.).
Section 6: The Opportunity
The opportunity is not to remove human reviewers. It is to stop wasting their time on the least relevant papers. AI-assisted screening works when teams set high-recall thresholds, document stopping rules, and train reviewers before deployment.
References
[1] Scott, Anna Mae, et al. “Systematic Review Automation Tools Improve Efficiency but Lack of Knowledge Impedes Their Adoption: A Survey.” Journal of Clinical Epidemiology, 2021.
[2] Chai, Kevin E. K., et al. “Research Screener: A Machine Learning Tool to Semi-Automate Abstract Screening for Systematic Reviews.” Systematic Reviews, 2021.
[3] Ferdinands, Gerbrich, et al. “Performance of Active Learning Models for Screening Prioritization in Systematic Reviews.” Systematic Reviews, 2023.
[4] Thomas, James, et al. “Machine Learning Reduced Workload With Minimal Risk of Missing Studies: Development and Evaluation of a Randomized Controlled Trial Classifier for Cochrane Reviews.” Journal of Clinical Epidemiology, 2021.
[5] Shemilt, Ian, et al. “Machine Learning Reduced Workload for the Cochrane COVID-19 Study Register.” Systematic Reviews, 2022.
[6] Carey, Niamh, Marie Harte, and Laura Mc Cullagh. “A Text-Mining Tool Generated Title-Abstract Screening Workload Savings.” Journal of Clinical Epidemiology, 2022.
[7] Matsui, K., et al. “Human-Comparable Sensitivity of Large Language Models in Identifying Eligible Studies Through Title and Abstract Screening.” Journal of Medical Internet Research, 2024.
[8] O’Connor, Annette M., et al. “A Question of Trust: Can We Build an Evidence Base to Gain Trust in Systematic Review Automation Technologies?” Systematic Reviews, 2019.
[9] Dai, Z. Y., et al. “Accuracy of Large Language Models for Literature Screening in Systematic Reviews.” Journal of Medical Internet Research, 2025.
[10] Abogunrin, Seye, et al. “How Much Can We Save by Applying Artificial Intelligence in Evidence Synthesis?” Frontiers in Pharmacology, 2025.

Leave a comment