Section 1: The Problem
Unemployment looks smaller on the headline chart than it feels on the ground. Across OECD countries, more than 5.5% of the active working-age population was unemployed in January 2024, and a broader measure of labor underutilization still sat at 12%, or more than one in eight working-age adults. Youth are hit harder: 12.5% of people ages 15 to 29 across the OECD were not in employment, education, or training in 2022 (OECD).
A big part of the problem is not only a lack of jobs. It is a lack of matching. Public employment services have to decide which job seekers need extra support, which firms are likely to hire soon, and which openings fit which people. Traditional systems often rely on simple rules, old taxonomies, or caseworker judgment. Those tools help, but they miss hidden hiring demand, struggle with fast-changing skills, and often spread scarce counseling time too thinly (Bach et al.; OECD).
This is exactly where data science fits. With administrative records, click data, vacancy histories, and local labor-market signals, modern systems can predict who is at risk of long-term unemployment, which firms are quietly about to hire, and which recommendations are worth a job seeker’s time. The appeal is simple: fewer wasted applications, better targeting of support, and faster re-employment.
Section 2: What Research Shows
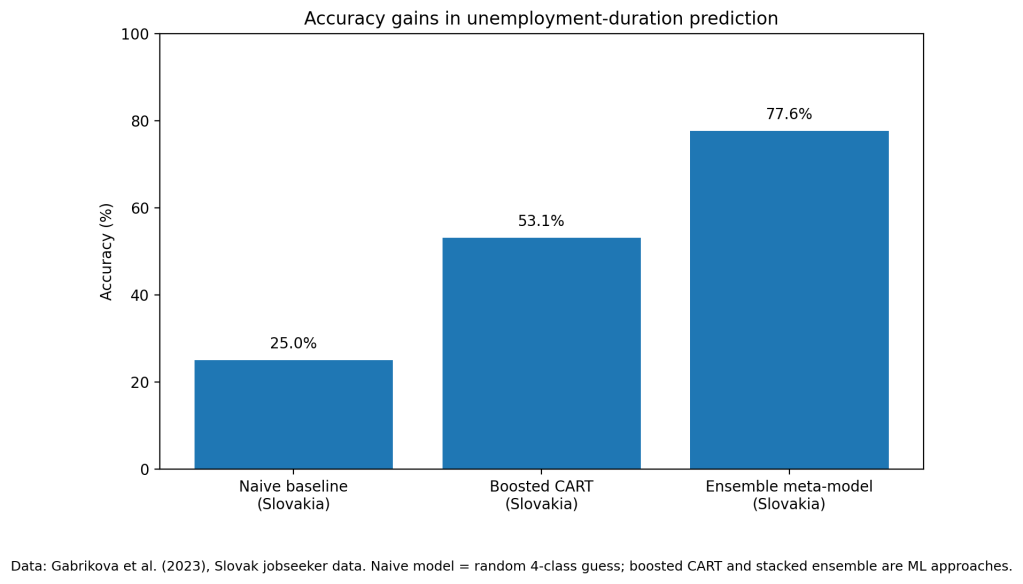
The retrospective evidence is strong. In Slovakia, Gabrikova et al. built a stacked ensemble model to predict unemployment duration across four categories. The final meta-model reached 77.6% overall accuracy on test data. A naive model that guessed randomly across the four classes would hit only 25%. For the most policy-relevant group, people unemployed for more than 12 months, the model reached 94% precision and 91.7% accuracy, which is the sort of signal a caseworker system can act on (Gabrikova et al.).
In Germany, Bach et al. compared several profiling models for predicting long-term unemployment. Their cross-validated ROC-AUC values ranged from 0.694 to 0.774, with gradient boosting performing best on key downstream classification measures. In the 2016 evaluation set, the gradient-boosting model detected 29% of long-term unemployment episodes when targeting the top 10% highest-risk cases, with 37.2% precision. When the threshold widened to the top 25%, recall rose to 57.7%, though precision fell to 29.6%. That is a classic policy tradeoff: catch more people, or spend resources more efficiently (Bach et al.).
A recent systematic review by Çelik Ertuğrul and Bitirim mapped 57 research papers on job recommender systems published between 2010 and 2023, alongside 19 survey articles. The review found that precision, recall, F1, ranking metrics, and increasingly hybrid ML and NLP methods dominate the field. The research base is no longer thin. The technical problem is not whether matching models work better than blunt rules. It is how to move them into everyday service delivery (Çelik Ertuğrul and Bitirim).
Section 3: What the Real World Shows
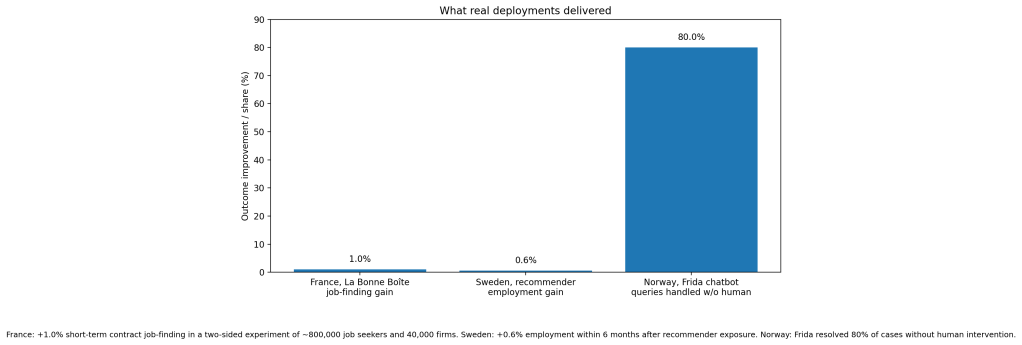
The strongest real-world evidence I found in this domain comes from very large field experiments. In France, Behaghel et al. evaluated La Bonne Boîte, a public recommendation platform run by the French employment service. Their two-sided randomized design covered about 800,000 job seekers and 40,000 establishments. The intervention produced a 1% increase in short-term-contract job-finding rates. More important, applications sent to recommended firms were 2.7 times more efficient than applications sent to the average firm in the platform’s universe. This is not a lab result. It is a live public system changing actual hiring outcomes (Behaghel et al.).
In Sweden, Le Barbanchon, Hensvik, and Rathelot deployed a collaborative-filtering job recommender on the country’s largest online job board and evaluated it with a clustered two-sided randomized experiment. Treated job seekers were more likely to click and apply to recommended jobs, and employment within six months rose by 0.6%. At the match level, recommending a vacancy increased the probability of working at that workplace by 5% (Le Barbanchon et al.).
There is also operational evidence beyond matching itself. OECD documented that Norway’s employment-service chatbot Frida handled a query load equivalent to 220 full-time employees during the pandemic’s early weeks and resolved 80% of cases without human intervention. That matters because matching systems do not help much if staff capacity collapses under intake, triage, and repetitive questions (OECD).
Section 4: The Implementation Gap
And yet adoption is still thin. OECD’s 2024 survey found that half of public employment services had implemented some AI tool at all, but only 20% used AI matching tools and only 17% used profiling tools. In other words, the flashy use case exists, the research base exists, but the core matching and targeting functions are still missing in most agencies (OECD).
One barrier is fairness. Desiere and Struyven found that in the Flemish public employment service, at a maximum-accuracy setting, job seekers of foreign origin who ultimately found work were 2.6 times more likely to be misclassified as high-risk than comparable native-origin job seekers. That kind of bias does not stay academic. It changes who gets pushed into which service track, who is seen as promising, and who is treated as a low-return case (Desiere and Struyven).
Another barrier is workflow design. Bach et al. show that even similarly accurate models can flag different people as high risk. That means implementation is not only a model-choice question. It is also a threshold-setting question, a governance question, and a budget question. Small design choices change who gets counseling, training, or employer outreach (Bach et al.).
Then there is human adoption. OECD points to bias concerns, explainability, staff resistance, lack of skills, and low trust as recurring obstacles. Agencies worry, reasonably, that a black-box tool will be politically explosive if it makes a bad call on a vulnerable worker. Staff worry it will undercut professional judgment. Low take-up can sink a good model before it has a fair chance to improve outcomes (OECD).
Section 5: Where It Actually Works
It works best when the tool is narrow, decision-support oriented, and plugged into an existing workflow. France’s La Bonne Boîte did not try to replace the labor market. It targeted a specific friction: hidden hiring demand at the firm-occupation level. Sweden’s recommender worked because it used behavioral data at scale and measured outcomes against registers, not self-reports. Norway’s chatbot worked because the task was high-volume and repetitive, with a clear escalation path to humans.
The pattern is clear. Systems succeed when they solve one operational bottleneck, keep humans in the loop, and make the gain visible in metrics staff care about: hires, case load, or response time.
Section 6: The Opportunity
The opportunity is not to hand unemployment policy over to algorithms. It is to use data science where labor markets are most obviously wasteful: bad targeting, weak vacancy discovery, and overloaded front-line staff. The evidence says these systems can improve matching. The gap is institutional, not technical.
Takeaways:
- Start with decision support, not automated denial or hard segmentation.
- Measure deployment with real outcomes, not only AUROC or offline accuracy.
- Audit subgroup error rates before rollout and keep auditing after rollout.
- Let caseworkers override the model, but log overrides and learn from them.
- Build tools around existing service bottlenecks such as vacancy targeting, triage, and follow-up.
Charts:
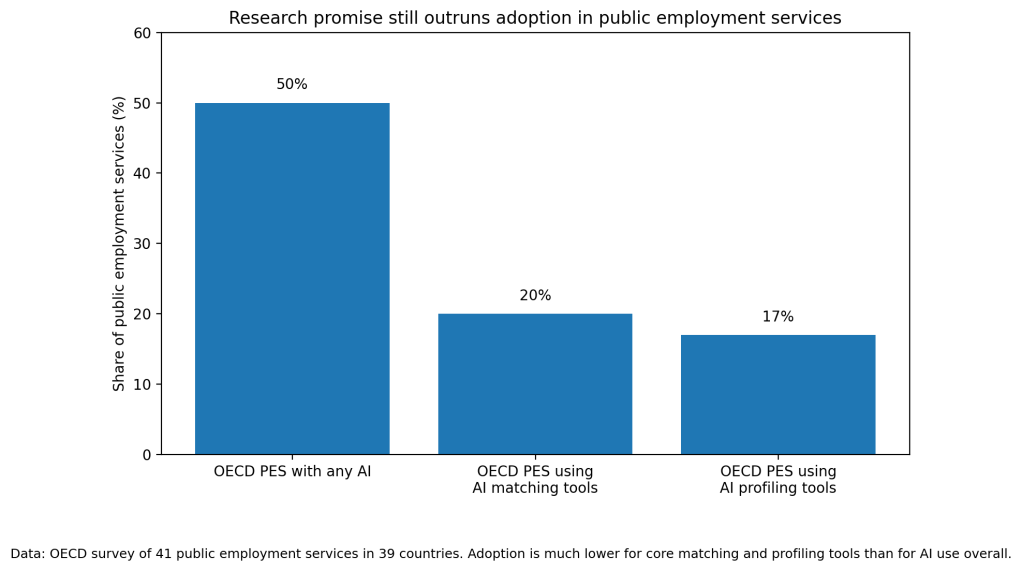
References
[1] Bach, Ruben L., et al. “The Impact of Modeling Decisions in Statistical Profiling.” Data & Policy, vol. 5, 2023, Cambridge University Press.
[2] Behaghel, Luc, et al. The Potential of Recommender Systems for Directing Job Search: A Large-Scale Experiment. IZA Discussion Paper No. 16781, 2024.
[3] Çelik Ertuğrul, Duygu, and Selin Bitirim. “Job Recommender Systems: A Systematic Literature Review, Applications, Open Issues, and Challenges.” Journal of Big Data, vol. 12, 2025, article 140.
[4] Desiere, Sam, and Ludo Struyven. “Using Artificial Intelligence to Classify Jobseekers: The Accuracy-Equity Trade-off.” Journal of Social Policy, vol. 50, no. 2, 2021, pp. 367-385.
[5] Gabrikova, Barbara, et al. “Machine Learning Ensemble Modelling for Predicting Unemployment Duration.” Applied Sciences, vol. 13, no. 18, 2023, article 10146.
[6] Le Barbanchon, Thomas, Lena Hensvik, and Roland Rathelot. How Can AI Improve Search and Matching? Evidence from 59 Million Personalized Job Recommendations. 2023 working paper.
[7] OECD. A New Dawn for Public Employment Services. OECD Artificial Intelligence Papers, 2024.
[8] OECD. Society at a Glance 2024: Unemployment. OECD Publishing, 2024.

Leave a comment