Section 1: The Problem
TSA screened over 904 million travelers in 2024, plus billions of carry-on items moving through checkpoints. One slow lane turns into a line, then missed flights, then real economic drag. Airports also sit at the center of national risk. One missed weapon or explosive is a catastrophe, and one bad rush-hour backlog strains staff and security at the same time. (TSA, PR Newswire)
Manual X-ray screening asks humans to spot rare threats inside cluttered bags, fast, for hours. Performance drops when bags get more cluttered and when items like laptops stay inside. Fatigue and low base rates make vigilance hard to sustain. (Akcay; Hügli)
Traditional upgrades often focus on hardware and rules, like “take laptops out.” That helps, but it shifts work onto passengers and still leaves the hardest part, deciding what the image means, to a tired human. The bottleneck stays cognitive. (Akcay)
Section 2: What Research Shows
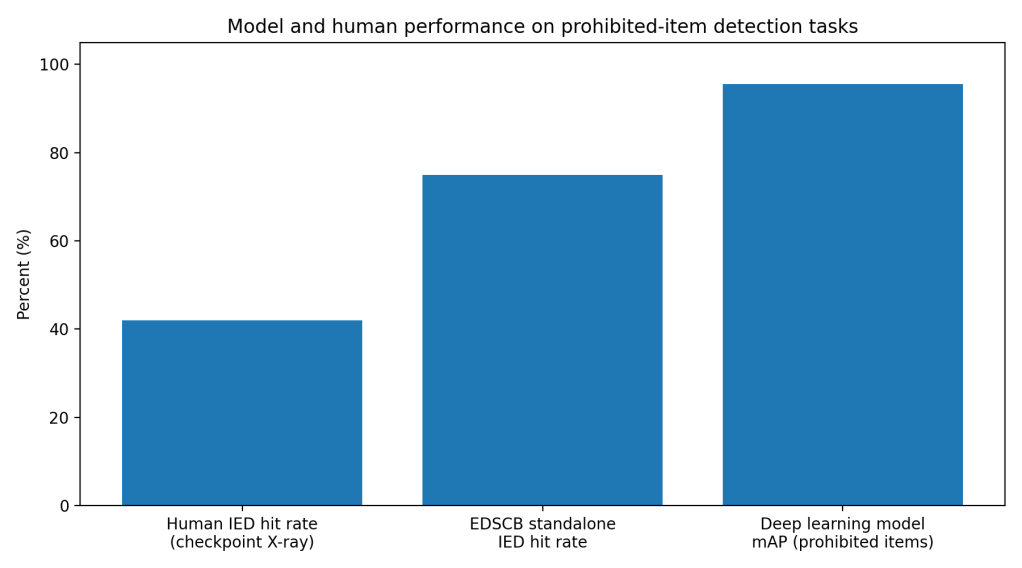
In lab and benchmark settings, modern deep learning models detect prohibited items in X-ray images with accuracy that looks solved on paper. A 2025 lightweight model reports 95.59% detection performance and a 1.86 percentage-point mAP gain over a YOLOv4-tiny baseline, while running at 122 FPS, which is fast enough for live systems. (Liang)
Another 2025 model reports mAP50–95 of 73.9% on SIXray, 43.9% on OPIXray, and 74.6% on CLCXray, while staying small enough for practical deployment. Those datasets reflect common real issues like occlusion and overlap, the stuff humans struggle with. (Zhao)
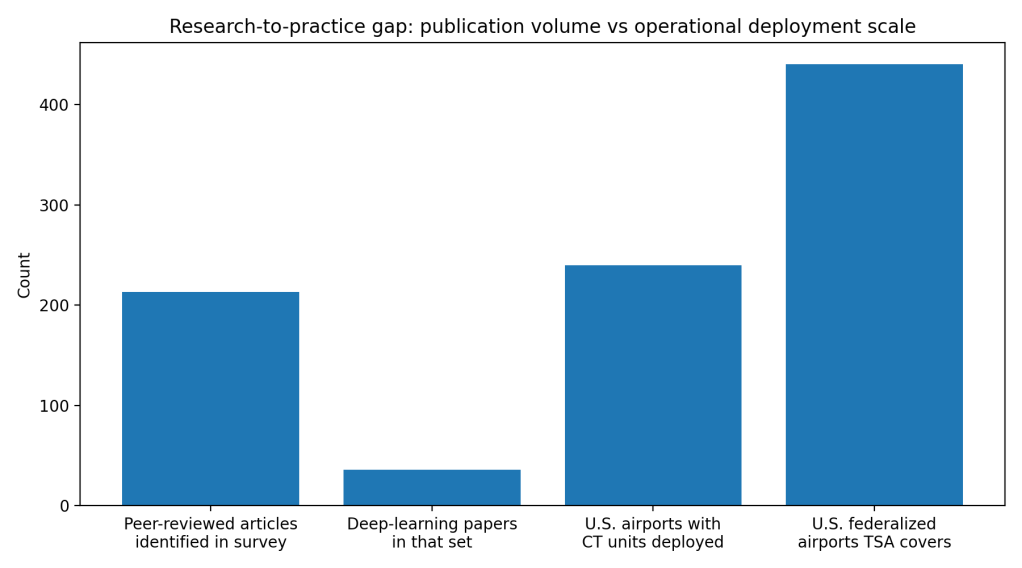
Surveys paint the same picture at scale. A major 2022 review identified about 213 relevant peer-reviewed articles in X-ray security imaging, including 36 deep-learning papers, and the field keeps growing. On metrics like mAP, sensitivity, and detection rates, deep models routinely beat older feature-based methods. (Akcay)
Section 3: What the Real World Shows
The story changes when models meet checkpoint behavior. A field-realistic study with professional screeners tested an Explosives Detection System for Cabin Baggage, EDSCB, as decision support. EDSCB alone hit 75% on IED targets with a 9% false alarm rate, and overall 83% correct decisions in the automation conditions. (Hügli)
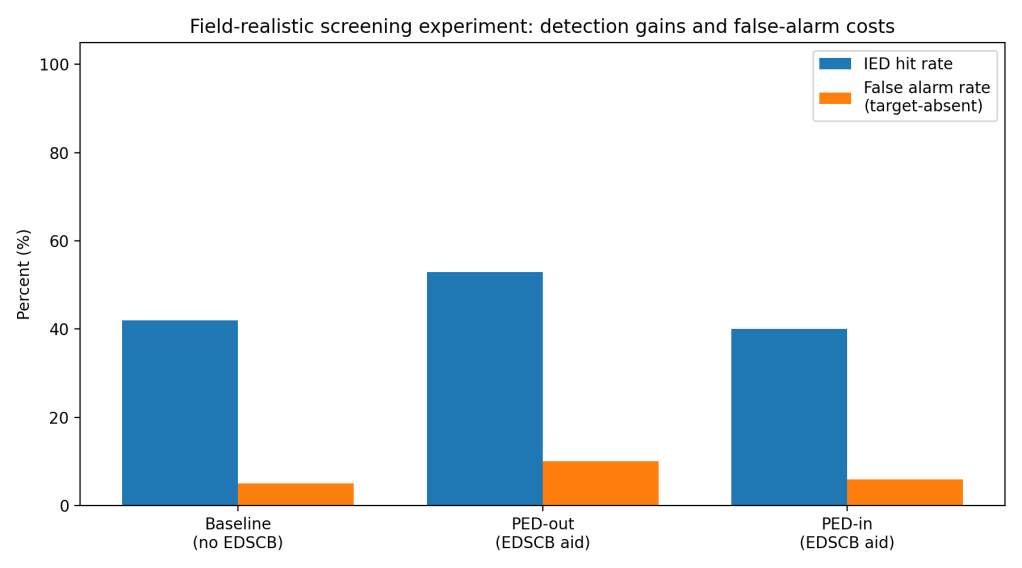
But the combined human–machine system underperformed the automation because humans did not consistently follow the alerts. For IEDs, mean hit rate sat around 0.42 at baseline, rose to about 0.53 when electronics were screened separately (PED-out), then fell back near 0.40 when electronics stayed inside bags (PED-in). The “cry-wolf” effect showed up, screeners ignored a large share of true alarms. (Hügli)
False alarms also carry real operational cost. In the same work, EDSCB use nearly doubled the human–machine false alarm rate when electronics were screened separately, from about 0.05 to about 0.10, which drives secondary checks and slows lanes. (Hügli)
A 2025 follow-up looked at failure modes like false alarms and miscues and reports IED hit rates around 0.93, 0.92, and 0.90 across conditions, showing strong potential, but also highlighting how small reliability shifts change human behavior and overall system performance. (Hügli)
Section 4: The Implementation Gap
False alarms do not only waste time. They train people to tune out alerts. In one experiment, when PEDs were outside bags, operator compliance with alarms averaged 0.58, but dropped to 0.46 when PEDs were inside, and screeners ignored 42% and 54% of true alarms in those conditions. That is not a model problem. That is a workflow problem. (Hügli)
On-screen alarm resolution creates a risky middle ground. Some settings still ask screeners to decide whether a highlighted region is harmless or a true explosive threat. That puts the hardest judgment, material interpretation in a cluttered image, back onto the human, right where fatigue and ambiguity hit hardest. (Hügli; TSI Magazine)
Deployment also runs into procurement and certification realities. Aviation security tech gets locked behind proprietary data, vendor ecosystems, and regulated testing. Research models train on public datasets, then face domain shift in the wild, different scanners, different image preprocessing, different threat types, different concealment tactics. That gap forces expensive re-validation and slows rollout. (Akcay; Zhao)
Finally, adoption is uneven even when hardware shows up. TSA reports more than 820 CT units deployed to more than 240 airports, while TSA security operations cover about 440 federalized airports. Protocols vary by airport, so the same traveler sees different rules and different screening flows, which signals partial integration rather than full system change. (TSA, Performance.gov)
Section 5: Where It Actually Works
It works when agencies treat the checkpoint as a human–machine system, not an AI model demo. The clearest win in the research comes from matching the workflow to what the automation does well. When electronics were screened separately, EDSCB improved IED detection versus baseline, because task difficulty stayed lower and screeners engaged with alerts more. (Hügli)
It also works when the response to an alarm is standardized. When a model flags a bag, the process needs to route it to a defined secondary action, not force a rushed on-screen judgment in primary screening. Studies argue for automated decisions or clear instructions to avoid miscues and missed prohibited items. (Hügli)
Section 6: The Opportunity
The tech is not waiting. Operations are.
Takeaways you can act on.
- Treat false alarms as a user-experience bug, not a rounding error. Track alarm rates per lane and per operator shift, then tune thresholds to the staffing reality. (Hügli)
- Stop mixing “decision support” with “decision responsibility” in primary screening. Use clear routing rules for alarms, especially for explosives signals. (Hügli; TSI Magazine)
- Validate models on scanner-specific, airport-specific data before full rollout, then re-check drift monthly, not yearly. (Akcay; Zhao)
- Measure system performance, not model performance. Report combined hit rate, false alarms, and throughput together, because tradeoffs decide adoption. (Hügli)
- Build trust with transparency. Show screeners what the system is good at, where it fails, and when to override it, using training tied to real failure modes. (Akcay; Hügli)
References
[1] Akcay, Samet, and Toby Breckon. “Towards Automatic Threat Detection: A Survey of Advances of Deep Learning within X-ray Security Imaging.” Pattern Recognition, vol. 122, 2022, p. 108245. DOI: 10.1016/j.patcog.2021.108245.
[2] Hügli, Dominik, et al. “Benefits of Decision Support Systems in Relation to Task Difficulty in Airport Security X-Ray Screening.” International Journal of Human-Computer Interaction, 2023. PDF: FHNW Institutional Repository.
[3] Hügli, Dominik, et al. “Effects of False Alarms and Miscues of Decision Support Systems on Human-Machine System Performance: A Study with Airport Security Screeners.” Ergonomics, 2025. PDF: FHNW Institutional Repository / PubMed record.
[4] Liang, Tian, et al. “A Study on Detection of Prohibited Items Based on X-Ray Images with Lightweight Model.” Sensors, vol. 25, no. 17, 2025, article 5462.
[5] Zhao, Kai, et al. “A Lightweight Xray-YOLO-Mamba Model for Prohibited Item Detection in X-ray Images Using Selective State Space Models.” Scientific Reports, vol. 15, 2025, article 13171.
[6] Transportation Security Administration. “2024 TSA Checkpoint Travel Numbers.” TSA.gov, 2024.
[7] Transportation Security Administration. “TSA Is Prepared for Busiest Summer Travel Season Ever.” TSA.gov press release, 16 May 2024.
[8] Performance.gov. “Transportation Security Administration, Domestic Aviation Operations.” performance.gov, accessed 2026.
[9] PR Newswire. “2024 Year in Review: TSA Highlights a Banner Year of Record Passenger Volumes, Customer Service Improvements and Technology Enhancements.” PR Newswire, 2025.
[10] TSI Magazine. “Single-View, Multi-View and 3D Imaging for Baggage Screening, What Should Be Considered for Effective Training?” TSI Magazine, 2019.

Leave a comment