The Problem
Every year, child protective services (CPS) in the United States field millions of reports of suspected child abuse or neglect. In 2023 alone, there were 4.4 million child maltreatment referrals, yet only about 546,000 children were confirmed as victims. This means the system is inundated with false alarms even as real abuse cases slip through. Tragically, an estimated 2,000 children died from abuse or neglect in 2023 – a rate that has grown ~30% in the last decade. Clearly, the human toll is immense. Beyond the heartbreaking loss of life, childhood maltreatment carries a lifetime economic burden estimated at $428 billion per year in the US when factoring health care, social services, and lost productivity. The stakes could not be higher: decisions made by CPS workers literally determine whether children are kept safe or left in harm’s way.
Despite the high stakes, today’s child welfare system relies largely on overburdened caseworkers using intuition and basic checklists. It’s estimated 1 in 3 American children will be the subject of a CPS investigation by age 18. Hotline workers must triage each call, often making gut calls about which families to investigate further. Not surprisingly, mistakes are common: some children are left in dangerous situations (false negatives), while others endure traumatic investigations or foster placement unnecessarily (false positives). One analysis found traditional actuarial risk tools in child welfare have an average predictive accuracy (AUC) of only ~0.66 (on a scale of 0.5=chance to 1.0=perfect). In practice, over 85% of hotline reports nationwide turn out unsubstantiated, yet in states like Florida and Washington, over half of the children who are confirmed victims had been reported at least once before. In other words, many truly high-risk kids were reported previously but not flagged for timely intervention. The status quo – a 20-year-old paper risk assessment or a harried caseworker’s gut feeling – is clearly falling short. As one county official bluntly put it, “The gut isn’t good at this”. There is a pressing need for better tools to help protect vulnerable children.
What Research Shows
In the last decade, data scientists and social workers have turned to machine learning (ML) for help. Retrospective studies demonstrate that ML-based predictive models can far outperform traditional methods in identifying at-risk children. For example, a 2024 Danish study trained algorithms on 100,000+ child protection cases and achieved an AUROC over 0.87 in predicting which children would later be removed from their homes for safety. This is a big jump from the roughly 0.60–0.70 accuracy of old checklists. In one U.S. county, a modern ML model (XGBoost) reached an AUC of 0.76 for flagging likely maltreatment cases, compared to 0.58–0.66 for legacy consensus-based or actuarial tools. These models crunch hundreds of data points – prior calls, criminal records, hospital visits, substance abuse history, etc. – to spot patterns no human could reliably juggle. The result is algorithms that can rank families by risk far more consistently than humans. Figure 1 below illustrates the accuracy gap between traditional risk assessments and an ML model.
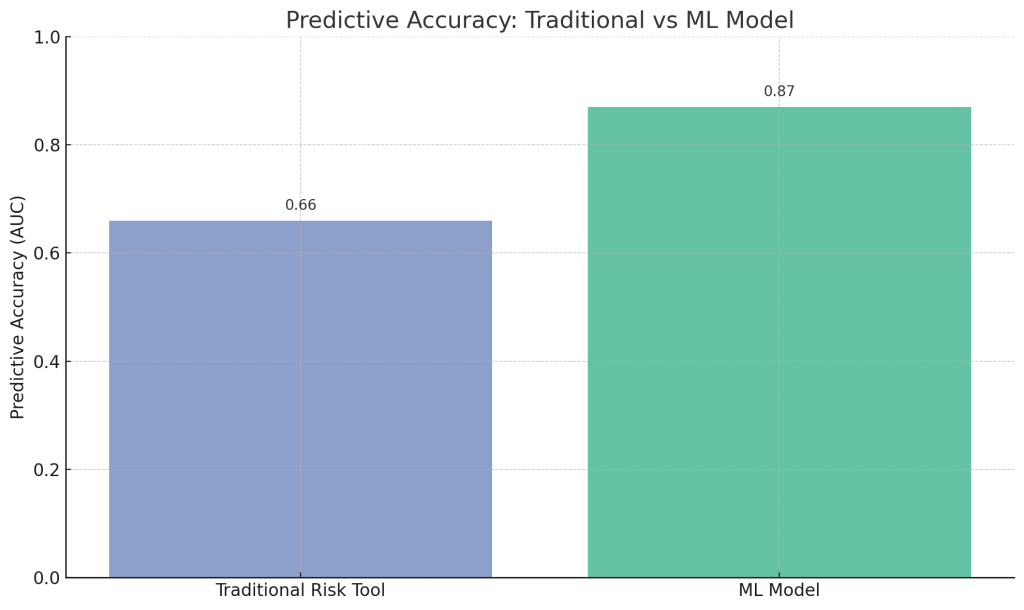
Figure 1: Predictive accuracy (AUROC) of traditional child welfare risk assessment tools vs. a modern machine learning model. Higher is better. ML models show substantially better accuracy in retrospective tests.
Research also shows these models can identify truly high-risk children earlier. In Pittsburgh, the Allegheny Family Screening Tool (AFST) was developed on historical data and found a strong correlation between the algorithm’s risk score and actual harm to children. Children the model rated in the top 5% risk tier had an injury-related hospitalization rate of 14.5 per 100, compared to 4.9 per 100 for low-risk children. In other words, the algorithm’s “high risk” label was a meaningful warning: those children were nearly three times more likely to later show up at a hospital injured. Importantly, these algorithms are designed not to simply rubber-stamp existing biases. Developers deliberately exclude race as a predictor, and early evidence suggested the tools could reduce subjective bias in decision-making. The AFST, for instance, focuses on predicting future confirmed harm (like foster placement or serious injury) rather than replicating subjective referral decisions. The goal is to catch more true dangers (fewer false negatives) while avoiding unnecessary trauma for safe families (fewer false positives). And because an algorithm can apply the same rules to every case, it can bring consistency and objectivity that individual caseworkers, with the best of intentions, often struggle to maintain.
What the Real World Shows
So the data science looks promising – but does it actually help kids when deployed in the field? There have been a few pioneering implementations and trials that we can learn from. The first and most cited is Allegheny County (Pittsburgh, PA), which launched an ML-based screening tool in 2016 to aid hotline call screeners. An independent evaluation by researchers at Stanford found the tool produced a “moderate” increase in screening accuracy: roughly 24 more children per month were correctly identified for investigation compared to the prior approach. Figure 2 shows this improvement in accurate case decisions after the algorithm’s introduction. Notably, critics feared the algorithm might reinforce racial biases, but the evaluation found “no large or consistent differences in outcomes across racial or ethnic groups.” In fact, follow-up studies suggest the AFST helped make decisions more equitable. The rate at which Black children were removed from their homes (a wrenching outcome often disproportionally affecting families of color) fell into line with the rate for white children. One analysis reported the Black–white gap in foster placement dropped by 70–100% after Allegheny implemented the algorithm. In short, more children who needed protection were being flagged, and the tough decisions of whom to investigate or remove became notably less biased than before.
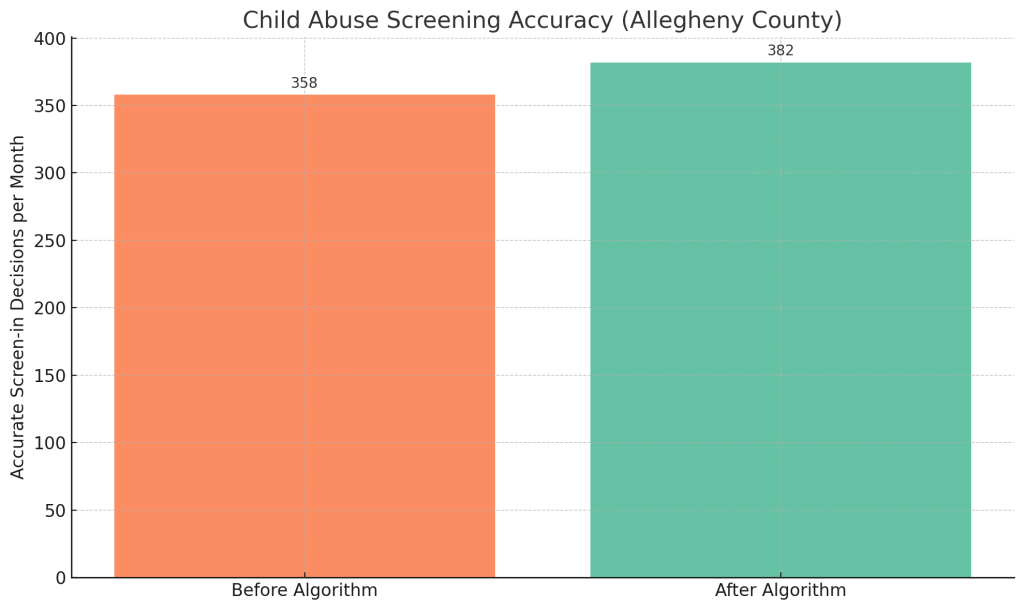
Figure 2: Real-world impact in Allegheny County – the number of children correctly identified for protective intervention rose from ~358 to ~382 per month after implementing an ML screening tool. This represents about two dozen more at-risk kids helped each month (with no increase in racial disparity).
Other jurisdictions’ experiences echo Allegheny’s cautious optimism. In Larimer County, Colorado, child welfare staff participated in a randomized controlled trial where some hotline teams had access to a predictive model and others did not. Preliminary results showed that families in the model-assisted group had fewer repeat abuse referrals than the control group – suggesting the interventions prompted by the algorithm improved child safety. Meanwhile, places like New York City, Oregon, and Colorado have deployed predictive analytics tools for several years and report that they help prioritize high-risk cases for closer review. These systems are typically used as a decision aid: the algorithm generates a risk score or tier, and supervisors use that along with their professional judgment – not as an automatic decision. Early adopters emphasize that the tool’s recommendations can “help workers pause and take a more holistic view” rather than relying on gut instinct alone. And unlike some past actuarial tools, the modern ML systems get updated and validated. For example, Allegheny’s model was retrained to predict only severe outcomes (child removal) after an earlier version including general re-referrals was deemed less useful. Ongoing refinements and transparency (publishing the methodology and independent audits) have been key to these implementations. The real world data so far shows ML models can work in practice – improving accuracy modestly, reducing racial bias, and helping social workers intervene earlier in high-risk situations.
The Implementation Gap
If the evidence is so encouraging, why haven’t these life-saving data tools been widely adopted? This is where the story gets complex. As of 2025, only a handful of state or county agencies use predictive risk models in child welfare – even though over half of U.S. states have explored or piloted them. Figure 3 highlights this gap: dozens of jurisdictions have tested the waters, but the vast majority of America’s child welfare agencies still rely on 20th-century methods. Several concrete barriers explain this implementation gap:
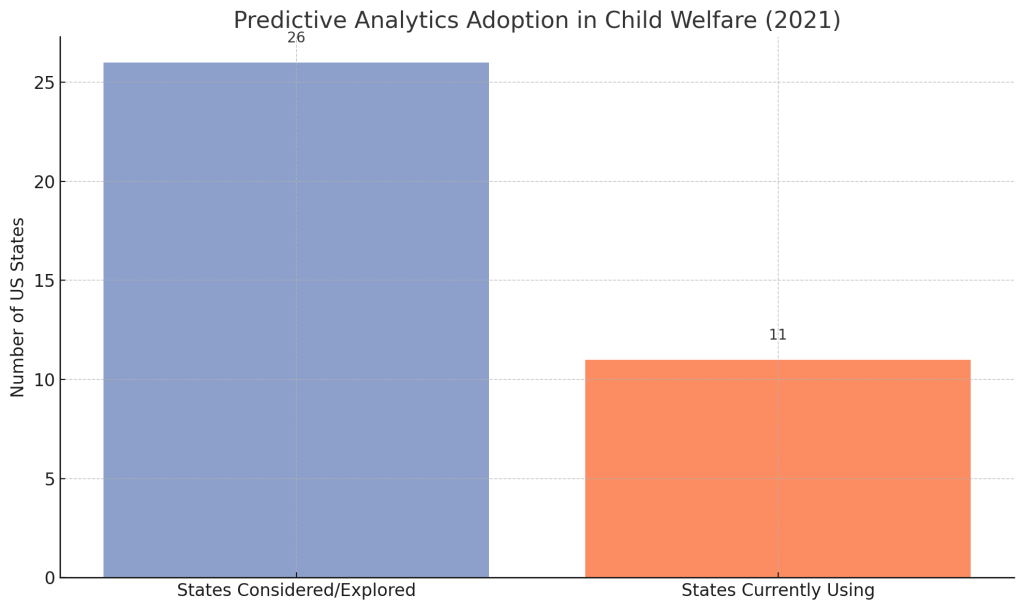
Figure 3: The research-to-practice gap in child welfare analytics. While by 2021 at least 26 states had considered or piloted predictive modeling, only around 11 states had any child welfare agencies actively using these tools. Most jurisdictions still have not adopted ML-driven decision support.
- Data and Technology Hurdles: Many agencies worry their data isn’t good enough to feed an algorithm. Child welfare databases are often outdated, fragmented, and missing data. Case info may be spread across child services, courts, schools, and hospitals that don’t talk to each other. As one county report put it, “aging systems and outdated data infrastructure slow caseworkers… eating into time staff could otherwise spend helping children.” Predictive models thrive on rich data, and agencies with siloed or messy records understandably fear “garbage in, garbage out”. Additionally, many state systems only compile statistics years after the fact (one federal system was 2 years behind), making timely prediction difficult. Upgrading decades-old IT and linking databases is no small task in the public sector.
- False Alarms and Trust: Early missteps have made some officials skittish. In 2017, Los Angeles County piloted a screening algorithm with a private vendor – and ended up dropping it after it “incorrectly identified an extremely high number” of false positives (over **3,800 children flagged high-risk who were not actually in danger). Flooding caseworkers with thousands of red alerts is a quick way to lose trust. If an algorithm isn’t precise, it can actually create more work and skepticism among staff. Likewise, a “black box” model that isn’t transparent about how it scores families will meet understandable resistance from social workers and the families themselves. The LA tool “lacked transparency about how variables influenced scores,” undermining user confidence. It’s a Catch-22: to improve the algorithms, agencies need to use them and iterate, but a few bad experiences can poison the well.
- Ethical and Equity Concerns: Perhaps the biggest barrier is the fear of making a biased system worse. Child welfare has a troubled history with racial and class disparities – and many advocates worry that surveillance algorithms will amplify these biases. The data used (e.g. arrest records, public assistance history) can reflect systemic discrimination. Civil liberties groups like the ACLU warn that these tools could unfairly target poor and minority families – effectively punishing parents for being poor, since “neglect” allegations often stem from poverty-related circumstances. In 2021, a U.N. report even criticized the U.S. for using data tools that “disproportionately impact low-income and minority families” in child welfare decisions. There’s also a broader “Big Brother” concern: families rarely consent to being evaluated by an algorithm, yet the outcome (a child removed or not) is as high-stakes as it gets. This has led to pushback and even calls to abolish such tools before they take root. In practice, the early adopters have taken steps to mitigate bias – for example, race is excluded as a predictor and results are monitored for disparity. And as noted, Allegheny’s experience was that a well-designed model can reduce racial disparities. But overcoming the perception of bias may require time and transparent evidence. Until stakeholders (frontline workers, community advocates, courts) trust the tools, widespread adoption will remain slow.
- Operational Challenges: Implementing ML in a human-centric field like social work also faces change management issues. Caseworkers might feel a loss of professional autonomy – “is a computer telling me how to do my job?” – or worry about liability if they follow a tool’s recommendation. Agencies have to train staff on how to interpret and appropriately use risk scores. This includes emphasizing that the model is a decision support, not a replacement for human judgment. Proper integration into workflows is key; otherwise the tool may be ignored or misused. Additionally, agencies need resources for ongoing model maintenance, validation, and support. Many county CPS departments run on tight budgets and high staff turnover, making any new program harder to sustain. It’s telling that of 21 agencies convened in a 2025 roundtable on this topic, only 4 had actually deployed predictive analytics – the rest were there to learn how to possibly get started. Clearly, bridging this gap will require not just technology, but leadership will, funding, and community buy-in to overcome the hesitations.
Where It Actually Works
Despite the hurdles, a few bright spots show that data-driven child protection can deliver on its promise under the right conditions. Allegheny County’s ongoing success is one example. Their Department of Human Services invested early in integrating data from many sources (child welfare, courts, jail, behavioral health, etc.), giving the AFST model a strong foundation. They also worked with academic experts and made the tool open to independent review, building credibility. After nearly a decade, Allegheny’s model is still in use, and its director reports it has “helped save time” for staff and led to “less biased decisions than gut alone.” Importantly, Allegheny built the tool in-house and retains control, allowing them to update it and ensure it’s used as intended (contrast this with places that bought a proprietary tool and couldn’t tweak it).
Another promising case is Douglas and Larimer Counties in Colorado, which partnered with the same research team to implement predictive screening models. Larimer’s model was even tested in an RCT, demonstrating improved outcomes as noted. These counties benefited from strong executive sponsorship and cross-agency collaboration (e.g. sharing data between welfare and eligibility systems). On the horizon, Idaho is launching a statewide predictive analytics program in 2026, explicitly designed to “enhance prevention services” and reduce repeated referrals. Idaho’s pilot will use the model not just to decide on investigations, but to connect high-risk families with support like substance abuse counseling or after-school programs. This preventative, assistance-oriented approach may avoid the “punitive” perception that doomed some other efforts. The common thread in these success stories is that technology was paired with human context and transparency. The algorithms were deployed as part of a broader strategy to improve how agencies help families, rather than as a magic black box. Where data science has been embraced in child welfare, it’s because leaders made the case that the tool would augment caseworkers’ expertise, not replace it – and then proved it through careful implementation and results.
The Opportunity
The gap between prediction and protection in child welfare can be closed. The research exists; the need is obvious. It will take concerted effort to translate those nifty ROC curves into real-world impact for kids. Here’s what could help turn proven data science into standard practice in our child welfare systems:
- Modernize Data Infrastructure: Agencies need investments to clean and unify their data. Upgrading antiquated case management systems and enabling data sharing across agencies (health, education, justice) will dramatically improve model performance. Funding dedicated to child welfare tech (as recommended by national county associations) can lay the groundwork for AI tools to function properly. Better data in means more trustworthy predictions out.
- Ensure Transparency and Oversight: To earn trust, predictive tools should be open to independent evaluation and community input. Agencies should publish validation results and avoid black-box algorithms. Regular audits for bias and accuracy by third parties (as the ACLU has called for) can reassure the public that the tool isn’t going unchecked. Clear guidelines should also define how the algorithm’s output is used in decisions, so it complements rather than overrides human judgment.
- Focus on Support, Not Surveillance: Framing matters. Using these models to offer help to families – connecting them to resources to mitigate risks – can flip the narrative from “spying on families” to preventing harm through early support. For example, if a newborn is flagged high-risk, the response could be a proactive offer of nurse home visits or parenting support, not an immediate investigation. This approach can build community buy-in and actually address root causes like poverty and mental health, reducing the need for foster care down the line.
- Empower and Train Caseworkers: Frontline staff should be partners in implementing predictive analytics. This means comprehensive training on how the tool works and how to interpret risk scores, as well as feedback mechanisms for workers to flag concerns or improvements. When caseworkers understand that the AI is there to lighten their load (by focusing attention where it’s needed), they’re more likely to use it. Crucially, maintaining human oversight – e.g. requiring supervisor review before acting on a high-risk score – can prevent over-reliance on the algorithm and catch any obvious errors.
- Sustain Funding and Leadership Support: Finally, closing the implementation gap will require champions at the federal, state, and local levels. Policymakers can provide grants or incentives (such as an enhanced federal funding match for states adopting approved predictive tools) to lower the barrier to entry. Visionary agency leaders need to drive the culture shift, as seen in Allegheny and Colorado. With stable funding, continuous improvement, and leadership commitment to ethical use, data science can become a normal part of child protection practice rather than a pilot project.
By seizing these opportunities, we can move from isolated pilot successes to a future where every child welfare agency has intelligent, fair decision-support at its fingertips. The technology alone won’t save lives – but deployed wisely, it can help the tireless humans in this system save more lives and strengthen more families. The data revolution has shown it can predict which children are in danger; now it’s up to us to act on it.
References
- USAFacts Team. “How many children experience abuse or neglect in the US?” USAFacts.org, updated Dec 5, 2025.
- Emnet Almedom, Nandita Sampath, and Joanne Ma. “Algorithms and Child Welfare: The Disparate Impact of Family Surveillance in Risk Assessment Technologies.” Berkeley Public Policy Journal, Feb 2, 2021.
- Michael Rosholm et al. “Predictive risk modeling for child maltreatment detection and enhanced decision-making: Evidence from Danish administrative data.” PLOS ONE, 19(9): e0289900, 2024.
- Child Welfare Monitor. “Using algorithms in child welfare: promise, confusion and controversy.” April 5, 2023.
- Sophia Fox-Sowell. “Why don’t more child welfare agencies use predictive risk models?” StateScoop, Dec 22, 2025.
- American Civil Liberties Union (ACLU). “Family Surveillance by Algorithm: The Rapidly Spreading Tools Few Have Heard Of.” Report, Sept 2021.
- Brian Rinker. “Predictive analytics in child welfare raise concerns.” Youth Today, Nov 17, 2021.
- Ning Zhu et al. “Assessing the Predictive Validity of Risk Assessment Tools in Child Health and Well-Being: A Meta-Analysis.” Children 12(4):478, 2025.
- Allegheny County DHS Analytics. “Summarizing Recent Research on Predictive Risk Models in Child Welfare.” April 2024.
- Jason Baron. “Using Predictive Risk Modeling to Improve Child Welfare Outcomes – Early Findings from a Randomized Trial.” Presentation at ACF Roundtable on Analytics, 2023.

Leave a comment