The Problem
Cities now spend billions each year responding to homelessness, yet far less on preventing it before people lose their homes. In the United States, more than 650,000 people were homeless on a single night in 2023, up 12% from the year before, and at least 1.5 million people cycle through shelters over a year. Episodes of homelessness are linked to higher mortality, emergency department use, and long‑term health and employment losses that ripple through families and communities.
Traditional prevention relies on referrals, self‑reported crisis, or simple screening tools like the VI‑SPDAT, which assigns scores based on short interviews about health, history, and risks. These tools are easy to use but have shown poor reliability and only weak links to who actually returns to homelessness, meaning scarce resources often go to households who are visible or vocal, not those most likely to lose housing. As rents outpace wages in many metro areas, this “first come, first served” or “highest self‑reported need” approach leaves many high‑risk households unseen until they show up at shelters.
Over the past decade, a different approach has emerged: using administrative data and machine learning to predict who is most likely to become homeless or to reenter the system, then targeting prevention money or housing slots to them. This is classic data science territory—large datasets, complex patterns, and decisions under budget constraints—but the real question is whether these tools actually improve outcomes and why they are still rare in practice.
What Research Shows
Retrospective modeling work suggests that machine learning can reliably identify people at high risk of homelessness or housing instability and often outperforms traditional statistical scores. In a study of U.S. Veterans’ Health Administration data, models predicting housing instability and homelessness using medical records achieved AUROC values of 0.85 for housing instability and 0.92 for homelessness with random forests, compared to 0.78 and 0.87 for logistic regression. By conventional standards, those machine learning models sit in the excellent discrimination range for homelessness and clearly outperform standard regression.
A Canadian study using shelter data from London, Ontario built an interpretable recurrent neural network (HIFIS‑RNN‑MLP) to predict chronic homelessness six months in advance. When compared to logistic regression baselines, the RNN‑MLP improved AUROC from about 0.74 to 0.83 by treating service use as time‑series data and incorporating both static and dynamic factors. The authors emphasized that this level of performance would allow communities to flag high‑risk clients early enough to offer housing interventions before people get stuck in years‑long shelter stays.
A 2025 scoping review of homelessness prediction models in high‑income countries found 15 studies, most using logistic or Cox regression, with a growing minority using machine learning methods like random forests, gradient boosting, and super learners. Across the literature, the review reported median AUROC around 0.78 for regression models versus about 0.84 for machine learning models, again pointing to consistent accuracy gains from richer algorithms. Yet, only two models had any external validation, and few reported calibration, underscoring how far most of this work remains from real‑world deployment.
Chart 1: Model accuracy vs. traditional methods
The figure below summarizes how machine learning compares to traditional models for predicting homelessness or housing instability.
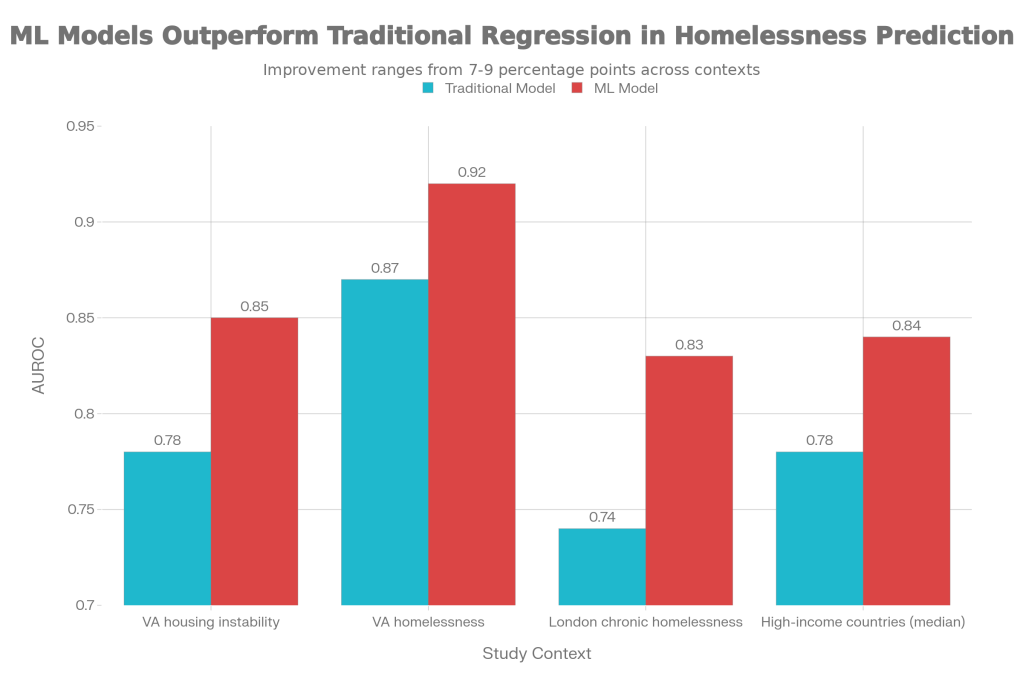
Predictive performance (AUROC) of traditional statistical models versus machine learning models for homelessness and housing instability risk
What the Real World Shows
When models do guide real decisions, the effects can be striking. In St. Louis, researchers used community‑wide homelessness management information system records and counterfactual machine learning (Bayesian Additive Regression Trees) to estimate which service—prevention, emergency shelter, rapid rehousing, or transitional housing—would best reduce a household’s chance of returning to the system. For 4,942 prevention‑eligible households, the model suggested prevention produced a 5.5–7.8 percentage‑point lower probability of reentry than alternative programs in simulations, meaning fewer households cycling back into homelessness under the same budget.
A separate line of work looks at targeted financial assistance rather than complex case services. In Santa Clara County, California, Destination: Home and Notre Dame’s Wilson Sheehan Lab for Economic Opportunities ran the first randomized controlled trial of a homelessness prevention program in the United States. Among households at imminent risk of eviction who applied to the Homelessness Prevention System between July 2019 and December 2020, those randomly offered short‑term assistance—averaging just under $2,000—were 81% less likely to be homeless within six months and 73% less likely within one year than similar eligible households who did not receive aid. The authors estimated the program generated about $2.47 in community benefits for every dollar spent, due to avoided shelter, health, and justice costs.
Meta‑analytic work also supports the idea that upstream housing interventions can meaningfully reduce homelessness when targeted well. A 2020 systematic review of Housing First programs found roughly 90% reductions in homelessness compared with “treatment first” approaches, largely by providing immediate permanent housing with supportive services instead of requiring treatment compliance first. A 2025 scoping review of homelessness prediction models concluded that such tools “have the potential to improve risk targeting and the effectiveness of preventive programs,” particularly when integrated with region‑level resource planning and cross‑sector collaboration.
The Implementation Gap
Despite promising accuracy and outcome data, predictive homelessness prevention is still rare in local housing systems. A big part of the problem is that most models are built retrospectively and never move beyond a research paper; the 2025 scoping review found only two externally validated models and virtually no prospective evaluations embedded in real housing workflows. Without external validation, managers worry the models will misclassify households in their own communities, especially where housing markets or demographics look different from the training data.
Existing tools that are widely used, like the VI‑SPDAT, illustrate the dangers of rolling out tools without strong predictive performance. Evaluations have shown that VI‑SPDAT scores are not stable over time—89% of people scored differently on a second administration—and that scores are only marginally associated with returns to homelessness once housed. In some studies, the type of housing support (e.g., rapid rehousing vs unsubsidized housing) predicted returns far better than the vulnerability score itself, and concerns about racial bias and weak validity have prompted some communities to withdraw or supplement the tool. This history makes providers wary of “the next algorithm,” even when newer models show higher AUROCs and better calibration.
Operational barriers also loom large. Implementing predictive models like the Los Angeles Homelessness Prevention Unit (HPU) requires linking multiple administrative datasets, maintaining secure data pipelines, and creating outreach teams to contact people before they show up for help. In Los Angeles County, the HPU model identified high‑risk individuals on public benefits who were several times more likely to experience homelessness than the general eligible population, but turning that list into timely, trusted offers of help required new units, contracts, and training. Many local continuums of care simply lack the analytic staff, legal frameworks, and IT capacity to operate such systems at scale.
Finally, there are real concerns about fairness, autonomy, and messaging. Communities worry that being “flagged” by a homelessness risk algorithm could feel stigmatizing or intrusive, especially when people did not directly consent to data linkage across agencies. Providers also fear that algorithms could quietly re‑encode existing inequities or be used to deny services rather than expand them, particularly if they are not transparent or accompanied by strong governance. All of this slows adoption, even where early evaluations show better targeting and large avoided costs.
Where It Actually Works
A few places show what it looks like when predictive prevention is embedded into real systems. In St. Louis, the counterfactual machine learning work was done in close partnership with local providers and used to craft transparent prioritization rules for specific subpopulations—such as families with children, unaccompanied youth, and people with comorbid health conditions—rather than issuing opaque “scores.” Simulations suggested these rules could reduce community‑wide homelessness and narrow disparities in reentry for female and youth households without excluding Black households or families with children, helping community leaders see the tool as an equity lever rather than a black box.
In California, Santa Clara County’s Homelessness Prevention System shows the power of combining simple targeting criteria with rigorous evaluation and clear messaging. The randomized trial demonstrated that relatively small, time‑limited cash assistance to high‑risk renters dramatically reduced subsequent homelessness and paid for itself in avoided downstream costs. Because the program worked within an existing community coalition and framed the tool as a way to expand help—not ration it—it gained political and provider support and is now scaling to assist at least 2,000 households per year.
The Opportunity
The evidence is clear: data‑driven targeting can predict homelessness risk with high accuracy and, when tied to real interventions, can keep people housed while saving public money. The gap is not the math; it is the messy work of validation, governance, integration, and trust‑building needed to make these tools routine parts of housing systems.
To move from pilots to practice, communities could:
- Build locally validated models, starting from existing open approaches but retraining and testing them on their own HMIS and benefits data.
- Pair prediction with guaranteed interventions, such as emergency financial assistance or prioritized rapid rehousing, so a “high risk” flag reliably triggers concrete help.
- Invest in data infrastructure and governance across housing, health, and social services, including privacy protections and community oversight bodies.
- Replace or complement weak tools like VI‑SPDAT with more accurate, interpretable models and regularly audit them for equity impacts.
- Design outreach and communication strategies that frame predictive prevention as supportive, not punitive, and involve people with lived experience in tool design.
Williams S. et al. “Predictive modeling of housing instability and homelessness in the Veterans Health Administration.” Psychiatry Research, 2018.
Nadeem M. et al. “Interpretable machine learning approaches to prediction of chronic homelessness.” Engineering Applications of Artificial Intelligence, 2021.
Kube A. et al. “Community- and data-driven homelessness prevention and service prioritization.” Journal of the American Medical Informatics Association, 2023.
Buckner S. et al. “Homelessness prediction models in high-income countries: A scoping review.” Forthcoming, 2025.
Brown M. et al. “Allocating Homeless Services After the Withdrawal of the VI-SPDAT.” Journal of Social Distress and Homelessness, 2021.
McLeod T. et al. “New Research on the Reliability and Validity of the VI-SPDAT.” Canadian Observatory on Homelessness, 2018.
U.S. Interagency Council on Homelessness. “Reducing homelessness in the U.S.: A research-based explainer.” 2025.
Destination: Home & Notre Dame LEO. “New 6-year randomized control trial: Prevention is a proven solution to keeping families housed.” 2023.
California Policy Lab. “A Proactive Approach to Preventing Homelessness in Los Angeles: The Homelessness Prevention Unit.” 2024.
OrgCode Consulting. “Service Prioritization Decision Assistance Tool (VI-SPDAT) 2.0 Manual.” 2014.

Leave a comment